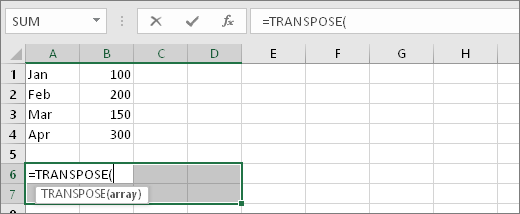
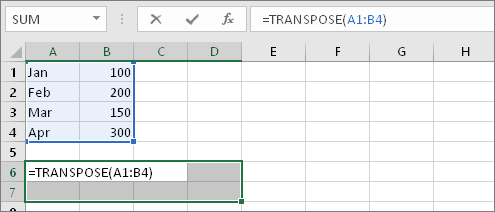
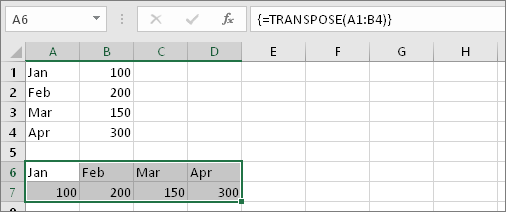
Physical path: F:/FACER_2020/Code
GitHub repo name where code is committed: FACER_2020
Please check https://github.com/shamsa-abid/FACER_Artifacts too
In F:/FACER_2020/Code/FACER/src/support/Constants.java
public static String PROJECTS_ROOT = "F:/FACER_2020/RawSourceCodeDataset/ClonedNew";
public static String DATABASE = "jdbc:mysql://localhost/faceremserepopoint5?useSSL=false&user=root";
public static String LUCENE_INDEX_DIR = "F:/FACER_2020/LuceneData/faceremserepo";
but now we get these settings from the command line as arguments. This is coded in the FACER repo Building Code file:
F:\FACER_2020\Code\FACER\src\sourcerer_parser_stmts\ParseContextAction.java
Two new csv files will be created in an output folder
F:\FACER_2020\Code\R\Nick1.R has the latest code but you will have to uncomment or modify csv fie names input and output.
Execute
F:\FACER_2020\Code\FASeR_Recommender\src\_0_AlphaCalculator\MCSMining.java
Your repo is ready
For Evaluation:
F:\FACER_2020\Code\FASeR_Recommender\src\automated_evaluation\Evaluation.java
GitHub repo name where code is committed: FACER_2020
Please check https://github.com/shamsa-abid/FACER_Artifacts too
In F:/FACER_2020/Code/FACER/src/support/Constants.java
public static String PROJECTS_ROOT = "F:/FACER_2020/RawSourceCodeDataset/ClonedNew";
public static String DATABASE = "jdbc:mysql://localhost/faceremserepopoint5?useSSL=false&user=root";
public static String LUCENE_INDEX_DIR = "F:/FACER_2020/LuceneData/faceremserepo";
but now we get these settings from the command line as arguments. This is coded in the FACER repo Building Code file:
F:\FACER_2020\Code\FACER\src\sourcerer_parser_stmts\ParseContextAction.java
Two new csv files will be created in an output folder
Running FACER Clustering and MCS detection
execute Rscript using the csv files to get the csv file containing cluster IDsF:\FACER_2020\Code\R\Nick1.R has the latest code but you will have to uncomment or modify csv fie names input and output.
Execute
F:\FACER_2020\Code\FASeR_Recommender\src\_0_AlphaCalculator\MCSMining.java
Your repo is ready
For Evaluation:
F:\FACER_2020\Code\FASeR_Recommender\src\automated_evaluation\Evaluation.java